


MapReduce
MapReduce is a programming model for data processing which written in various languages.
MapReduce programs are inherently parallel, thus putting very large-scale data analysis into the hands of anyone with enough machines.
We will introduce "MapReduce" concepts with weather dataset.
A Weather Dataset
The data we will use is from the National Climatic Data Center, or NCDC. The data is stored using a line-oriented ASCII format, in which each line is a record Dataset
1. Analyzing the Data with Unix Tools
We wants to know What’s the highest recorded global temperature for each year in the dataset?
We will answer this first without using Hadoop, The classic tool for processing line-oriented data is awk
A program for finding the maximum recorded temperature by year from NCDC weather records
#!/usr/bin/env bash
for year in all/*
do
echo -ne `basename $year .gz`"\t"
gunzip -c $year | \
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
done
The script loops through the compressed year files, first printing the year, and then processing each file using awk. The awk script extracts two fields from the data: the air temperature and the quality code. The air temperature value is turned into an integer by adding 0. Next, a test is applied to see whether the temperature is valid (the value 9999 signifies a missing value in the NCDC dataset) and whether the quality code indicates that the reading is not suspect or erroneous. If the reading is OK, the value is compared with the maximum value seen so far, which is updated if a new maximum is found. The END block is executed after all the lines in the file have been processed, and it prints the maximum value. Here is the beginning of a run:
% ./max_temperature.sh
1901 317
1902 244
1903 289
1904 256
1905 283…
The complete run for the century took 42 minutes in one run on a single EC2 High-CPU Extra Large instance.
To speed up the processing, we need to run parts of the program in parallel, There are a few problems with this solution such as
- dividing the work into equal-size pieces isn’t always easy.
- combining the results from independent processes may require further processing.
- you are still limited by the processing capacity of a single machine
Although it’s feasible to parallelize the processing, in practice it’s messy. Using a framework like Hadoop to take care of these issues is a great help.
2. Analyzing the Data with Hadoop
To take advantage of the parallel processing that Hadoop provides, we need to express our query as a MapReduce job. After some local, small-scale testing, we will be able to run it on a cluster of machines
Map and Reduce
MapReduce works by breaking the processing into two phases: the map phase and the reduce phase. Each phase has key-value pairs as input and output
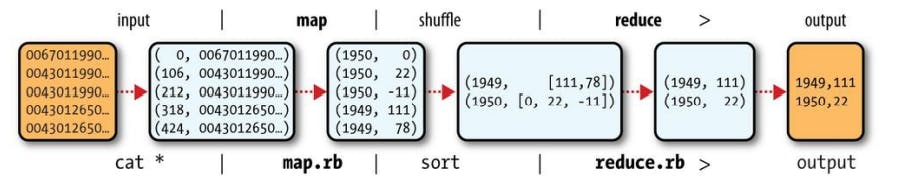
To visualize the way the map works, consider the following sample lines of input data
006701199099999*1950*051507004...9999999N9+000*0*1+99999999999...
004301199099999*1950*051512004...9999999N9+00*22*1+99999999999...
004301199099999*1950*051518004...9999999N9-00*11*1+99999999999...
004301265099999*1949*032412004...0500001N9+0*111*1+99999999999...
004301265099999*1949*032418004...0500001N9+00*781*+99999999999...
Map
Our map function is simple. We pull out the year and the air temperature, because these are the only fields we are interested in. In this case, the map function is just a data preparation phase, setting up the data in such a way that the reduce function can do its work on it, so
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
The output from the map function is processed by the MapReduce framework
Shuffle and sort
(1949, [111, 78])
(1950, [22, 0, -11])
Reduce
Each year appears with a list of all its air temperature readings. All the reduce function has to do now is iterate through the list and pick up the maximum reading.
(1949, 111)
(1950, 22)
The whole data flow
Scaling Out
You’ve seen how MapReduce works for small inputs; now it’s time to take a bird’s-eye view of the system and look at the data flow for large inputs. For simplicity, the examples so far have used files on the local filesystem. However, to scale out, we need to store the data in a distributed filesystem "HDFS" .
Data Flow
MapReduce job is a unit of work that the client wants to be performed.
Hadoop runs the job by dividing it into tasks, of which there are two types:
- Map tasks.
- Reduce tasks.
The tasks are scheduled using YARN and run on nodes in the cluster.
Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits, or just splits. Hadoop creates one map task for each split, which runs the user-defined map function for each record in the split.
For most jobs, a good split size tends to be the size of an HDFS block, which is 128 MB by default, although this can be changed for the cluster.
Hadoop does its best to run the map task on a node where the input data resides in HDFS, because it doesn’t use valuable cluster bandwidth. This is called the data locality optimization.
It should now be clear why the optimal split size is the same as the block size: it is the largest size of input that can be guaranteed to be stored on a single node and achieve data locality optimization.
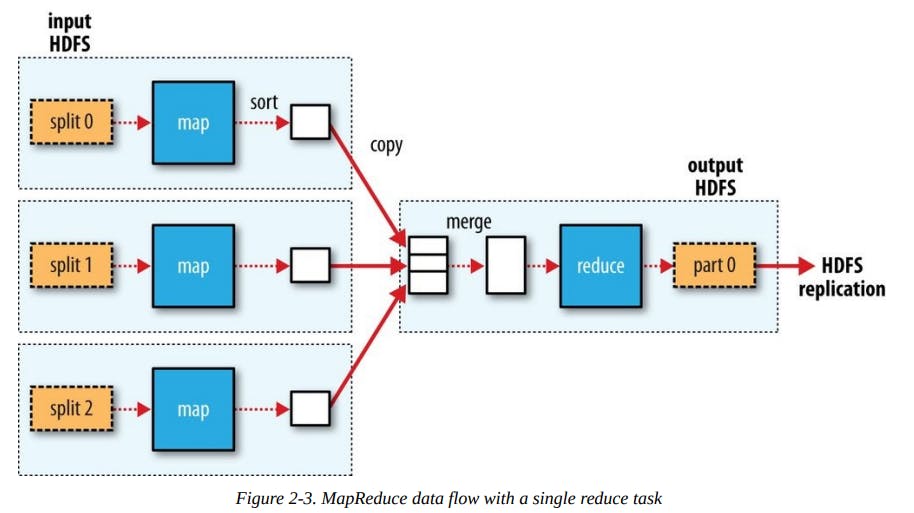
Map tasks write their output to the local disk, not to HDFS. Why is this? Map output is intermediate output: it’s processed by reduce tasks to produce the final output, and once the job is complete, the map output can be thrown away, so Reduce tasks don’t have the advantage of data locality.
Show data transfers between nodes:
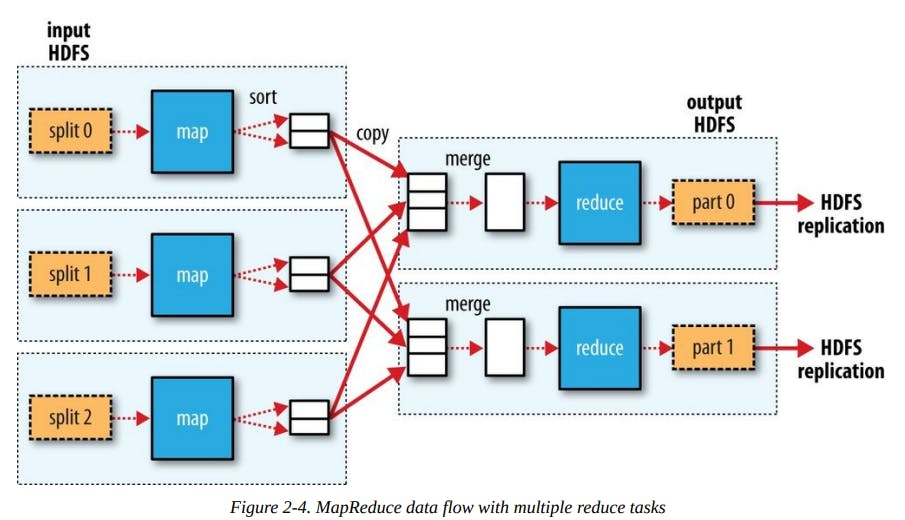
When there are multiple reducers, the map tasks partition their output, each creating one partition for each reduce task.
Combiner Functions
Many MapReduce jobs are limited by the bandwidth available on the cluster, so it pays to minimize the data transferred between map and reduce tasks. Hadoop allows the user to specify a combiner function to be run on the map output.
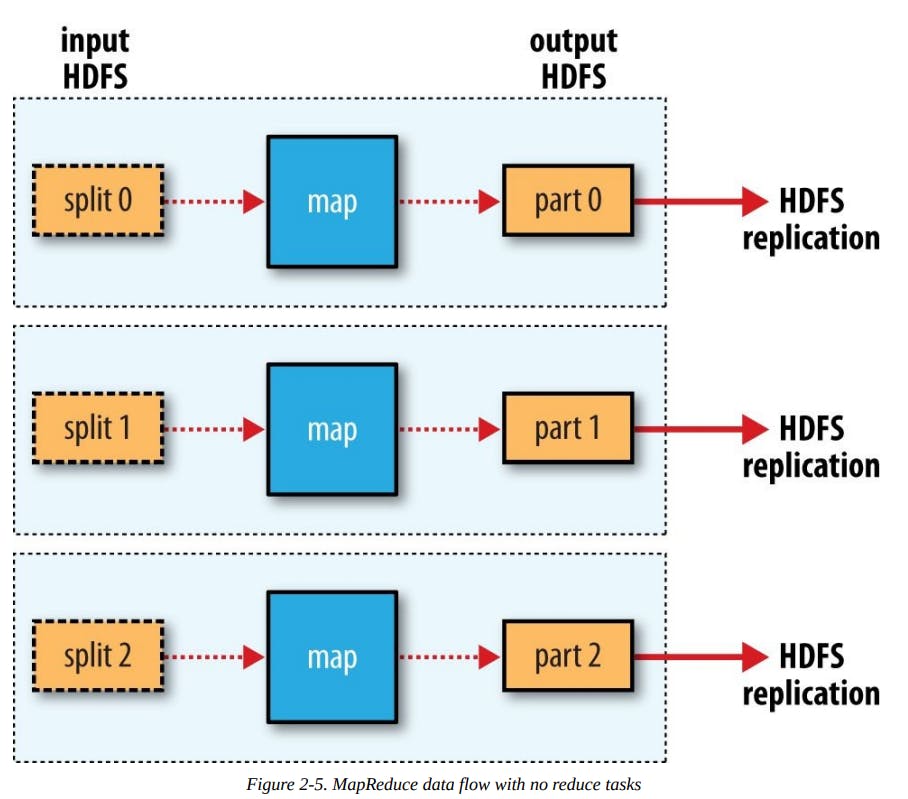
Zero reduce tasks
Finally, it’s also possible to have zero reduce tasks. This can be appropriate when you don’t need the shuffle because the processing can be carried out entirely in parallel.
Hadoop Streaming
Hadoop provides an API to MapReduce that allows you to write your map and reduce functions in languages other than Java. Hadoop Streaming uses Unix standard streams as the interface between Hadoop and your program, so you can use any language that can read standard input and write to standard output to write your MapReduce program.