


Meet Hadoop
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers. — Grace Hopper
Data!
We live in the data age. It’s not easy to measure the total volume of data stored electronically, but an IDC estimate put the size of the “digital universe” at 4.4 zettabytes in 2013 and is forecasting a tenfold growth by 2020 to 44 zettabytes.
This flood of data is coming from many sources
It has been said that “more data usually beats better algorithms”. The good news is that big data is here. The bad news is that we are struggling to store and analyze it.
Data Storage and Analysis
Although the storage capacities of hard drives have increased massively over the years
One typical drive from 1990 could store 1,370 MB of data and had a transfer speed of 4.4 MB/s, so you could read all the data from a full drive in around five minutes. Over 20 years later, 1-terabyte drives are the norm, but the transfer speed is around 100 MB/s, so it takes more than two and a half hours to read all the data off the disk.
This is a long time to read all data on a single drive, the way to reduce the time is to read from multiple disks at once.
Imagine if we had 100 drives, each holding one hundredth of the data. Working in parallel, we could read the data in under two minutes.
This solution may seem wasteful, But we can store 100 datasets, each of which is 1 terabyte, and provide shared access to them. We can imagine that the users of such a system would be happy to share access in return for shorter analysis times
The first problem
Hardware failure, a common way of avoiding data loss is through replication that done by the system.
The second problem
Most analysis tasks need to be able to combine the data in some way, and data read from one disk may need to be combined with data from any of the other 99 disks, but doing this correctly is notoriously challenging, MapReduce provides a programming model that abstracts the problem from disk reads and writes, transforming it into a computation over sets of keys and values.
What Hadoop provides
- Reliable
- Scalable
- Because it runs on commodity hardware and is open source,Hadoop is affordable
Querying All Your Data
MapReduce may seem like a brute-force approach. The premise is that the entire dataset — or at least a good portion of it — can be processed for each query. But this is its power
MapReduce is a batch query processor, and the ability to run an ad hoc query against your whole dataset and get the results in a reasonable time
Beyond Batch
MapReduce is fundamentally a batch processing system, and is not suitable for interactive analysis.
The real enabler for new processing models in Hadoop was the introduction of YARN (which stands for Yet Another Resource Negotiator) in Hadoop
YARN is a cluster resource management system, which allows any distributed program (not just MapReduce) to run on data in a Hadoop cluster.
There has been a flowering of different processing patterns that work with Hadoop. Here is a sample:
- Interactive SQL
- By dispensing with MapReduce and using a distributed query engine
- Iterative processing
- Stream processing
- Search
Despite the emergence of different processing frameworks on Hadoop, MapReduce still has a place for batch processing, and it is useful to understand how it works since it introduces several concepts that apply more generally.
Comparison with Other Systems
Hadoop isn’t the first distributed system for data storage and analysis.
Relational Database Management Systems
Why can’t we use databases with lots of disks to do large-scale analysis? Why is Hadoop needed? because of seeking time, Seeking is the process of moving the disk’s head to a particular place on the disk to read or write data.
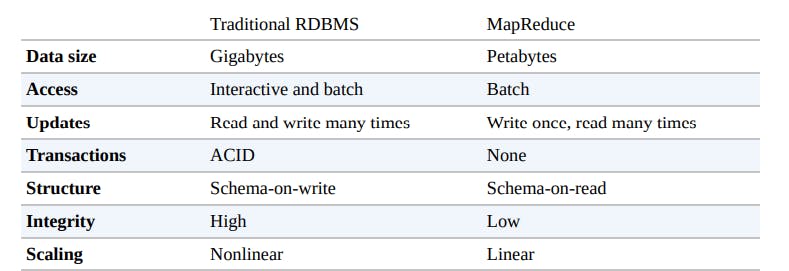
RDBMS compared to MapReduce
For updating a small proportion of records in a database, a traditional B-Tree (the data structure used in relational databases, which is limited by the rate at which it can perform seeks) works well. For updating the majority of a database, a B-Tree is less efficient than MapReduce, which uses Sort/Merge to rebuild the database.
In many ways, MapReduce can be seen as a complement to a Relational Database Management System (RDBMS)
MapReduce is a good fit for problems that need to analyze the whole dataset
An RDBMS is good for point queries or updates, where the dataset has been indexed to deliver low-latency retrieval and update times of a relatively small amount of data.
MapReduce suits applications where the data is written once and read many times, whereas a relational database is good for datasets that are continually updated
Hadoop systems such as Hive are becoming more interactive (by moving away from MapReduce) and adding features like indexes and transactions that make them look more and more like traditional RDBMSs.
RDBMS store structured data is organized into predefined format.
Relational data is often normalized to retain its integrity and remove redundancy
Hadoop works well on unstructured or semi-structured data because it is designed to interpret the data at processing time (so called schema-on-read). This provides flexibility and avoids the costly data loading phase of an RDBMS, since in Hadoop it is just a file copy.
Normalization poses problems for Hadoop processing because it makes reading a record a nonlocal operation
A Brief History of Apache Hadoop
Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open source web search engine, itself a part of the Lucene project